
Art is experienced as a flow of information between an artist and an observer. Should the latter be impaired in the principal sense which the artwork is aimed at however, a barrier appears. Such is the case for visually impaired people and paintings, for instance. The Synesthetic Variational Autoencoder attempts to overcome this obstacle by translating a painting's visual information into a more accessible sensory modality, namely music.
The Synesthetic Variational Autoencoder (SynVAE) is an unsupervised machine learning model which leverages properties of single-modality VAEs [1] in order to perform cross-modal translations. In this project, a visual VAE and MusicVAE [2] are combined in order to translate images into audio. This involves encoding an input image into music and then reconstructing it based on that audio alone. The model needs to stay as close as possible to the original while mainting consistency across sensory modalities. Similar looking images should therefore translate into similar sounding music. Below, you are welcome to explore image-music pairs from this project's experiments.




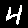



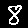


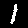


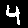





The classic MNIST dataset [3] contains monochrome images of handwritten digits and is used in many baseline machine learning tasks. Musical representations for identical digits sound noticably similar to each other when compared to different digits. A qualitative study confirmed that human listeners are able to distinguish between the digits "0", "1" and "4" with 73% accuracy by ear alone.




















CIFAR-10 [4] contains small photographs of 10 distinct object classes. In contrast to the simpler MNIST data, SynVAE learns to prioritize higher-level features such as object placement and colour. A red car may therefore share more similarities with other red objects than with a car of a different colour.




















The Behance Artistic Media dataset (BAM) [5] contains ∼2.3m annotated contemporary works of visual art of which we focus specifically on oil and watercolour paintings. Musical representations tend to encode higher-level information such as colour and overall structure. In a qualitative study, human evaluators were able to distinguish between images of 3 different emotion labels with 71% accuracy.























Vincent van Gogh's expansive breadth of artworks offers a unique environment for SynVAE. As a proof of concept, ∼1000 musically translated artworks from the Van Gogh Museum’s permanent collection are available to download below. With a pre-trained model this translation process takes less than one minute to complete. The archive contains artwork thumbnails and associated MIDIs as well as meta-data and is available for non-commercial use.